在前面的章节中,你发现了什么是Apache Spark,以及如何构建简单的应用程序,并且,希望你能理解关键概念,包括数据框架和懒惰。第5章和第6章是有联系的:你将在本章中构建一个应用程序,并在第6章中部署它。
在本章中,你将从零开始,构建一个应用程序。你之前在本书中构建了应用程序,但它们总是需要在最开始的时候摄取数据。你的实验室将在Spark内部和通过Spark生成数据,避免了摄取数据的需要。在集群中摄取数据比创建一个自生成的数据集要复杂一些。这个应用的目标是计算近似π(pi)的值。
然后,您将了解与Spark交互的三种方式。
本地模式,你已经通过前几章的例子熟悉了。
集群模式
交互式模式
LAB 本章的例子可以在GitHub上找到:https://github.com/jgperrin/net.jgp.books.spark.ch05。
一个无摄取数据的例子
在本节中,你将在一个不需要摄取数据的例子上工作。摄取是整个大数据过程中的一个关键部分,你在本书的许多例子中已经看到了。然而,本章将把你带到部署,包括在集群上的部署,所以我不希望你因为摄取数据而分心。
在集群上工作意味着数据对所有节点都是可用的。要了解集群上的部署,你需要花大量时间关注数据分布。你将在第6章学习更多关于数据分布的知识。
因此,为了简化对部署的理解,我跳过摄取,专注于理解所有的组件、数据的流向和实践部署。Spark会生成一个大型的随机数据集(自生成),可以用来计算π。
计算π
在这个小的理论部分,我将解释如何使用飞镖计算π,以及如何在Spark中实现这个过程。如果你讨厌数学,你会发现这一部分并不可怕(如果你对数学过敏,你可以跳过它)。尽管如此,我还是想把这一节献给我的大儿子Pierre-Nicolas,他肯定比我更能体会到这个算法的美妙。
你还在看?很好!在这短短的一节中,你将学习如何通过投掷飞镖来获得π的近似值,然后在Spark中实现代码。结果和实际代码在下一节。
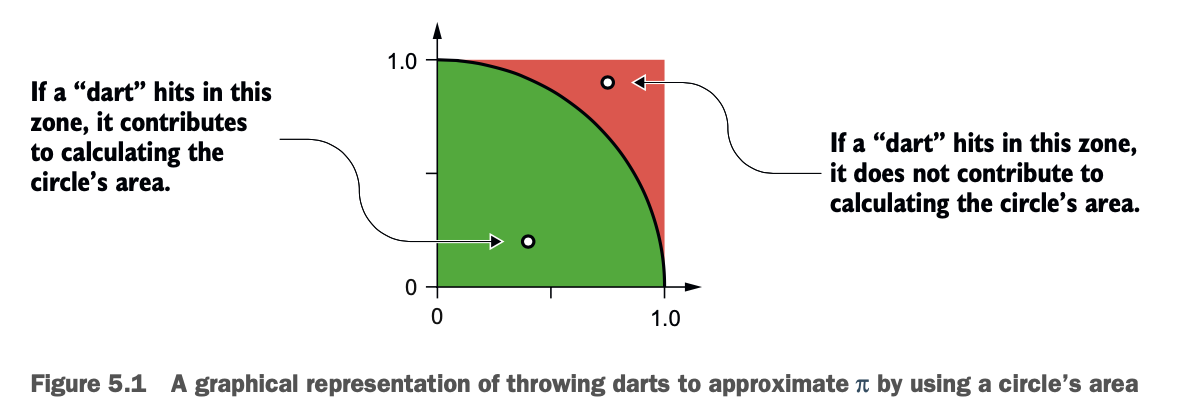
π的计算方法有很多(更多内容请参见维基百科 https://en.wikipedia.org/wiki/Approximations_of_%CF%80)。最适合我们方案的一种叫做求圆的面积,如图5.1所示。
这段代码通过向一个圆 "投掷飞镖 "来估计π:由于点(飞镖的冲击力)随机分散在单位正方形内,有些点落在单位圆内。随着点的增加,圆内的点的分数接近π/4。
你将模拟投掷数百万个飞镖。你将随机生成每次投掷的scscissa(x)和ordinate(y)。从这些坐标,使用毕达哥拉斯定理,你可以计算飞镖是在或不在。图5.2说明了这个措施。
 根据图5.2,你可以观察两个抛物线t1和t2,可以看到第一个抛物线t1在圆外,它的坐标是x1=0.75,y1=0.9。其坐标为x1=0.75,y1=0.9。距离d1是t1与原点之间的距离,其坐标为(0,0)。这用下面的公式表示。
根据图5.2,你可以观察两个抛物线t1和t2,可以看到第一个抛物线t1在圆外,它的坐标是x1=0.75,y1=0.9。其坐标为x1=0.75,y1=0.9。距离d1是t1与原点之间的距离,其坐标为(0,0)。这用下面的公式表示。
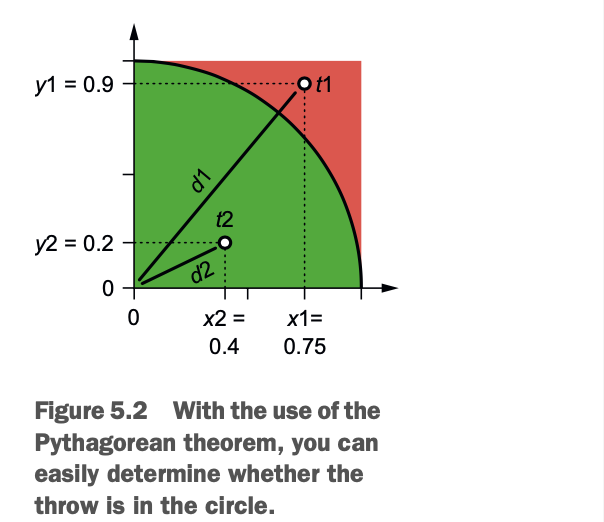
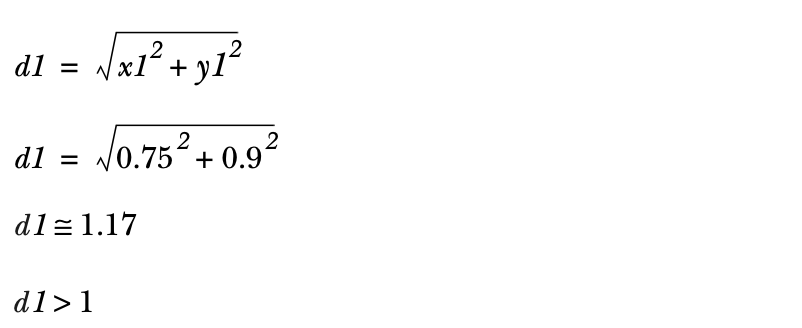 你可以对第二次投掷做同样的练习,其中d2代表原点和t2之间的距离。
你可以对第二次投掷做同样的练习,其中d2代表原点和t2之间的距离。
 这意味着第二次投掷是在圈内。
这意味着第二次投掷是在圈内。
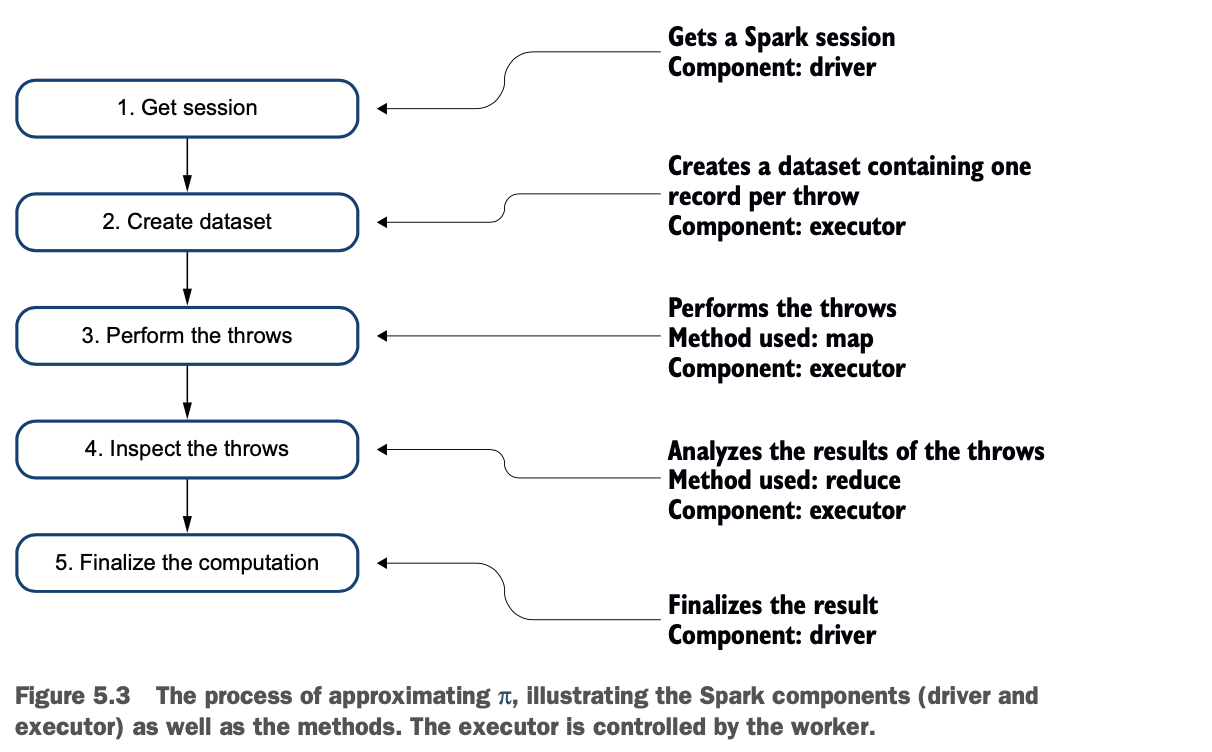
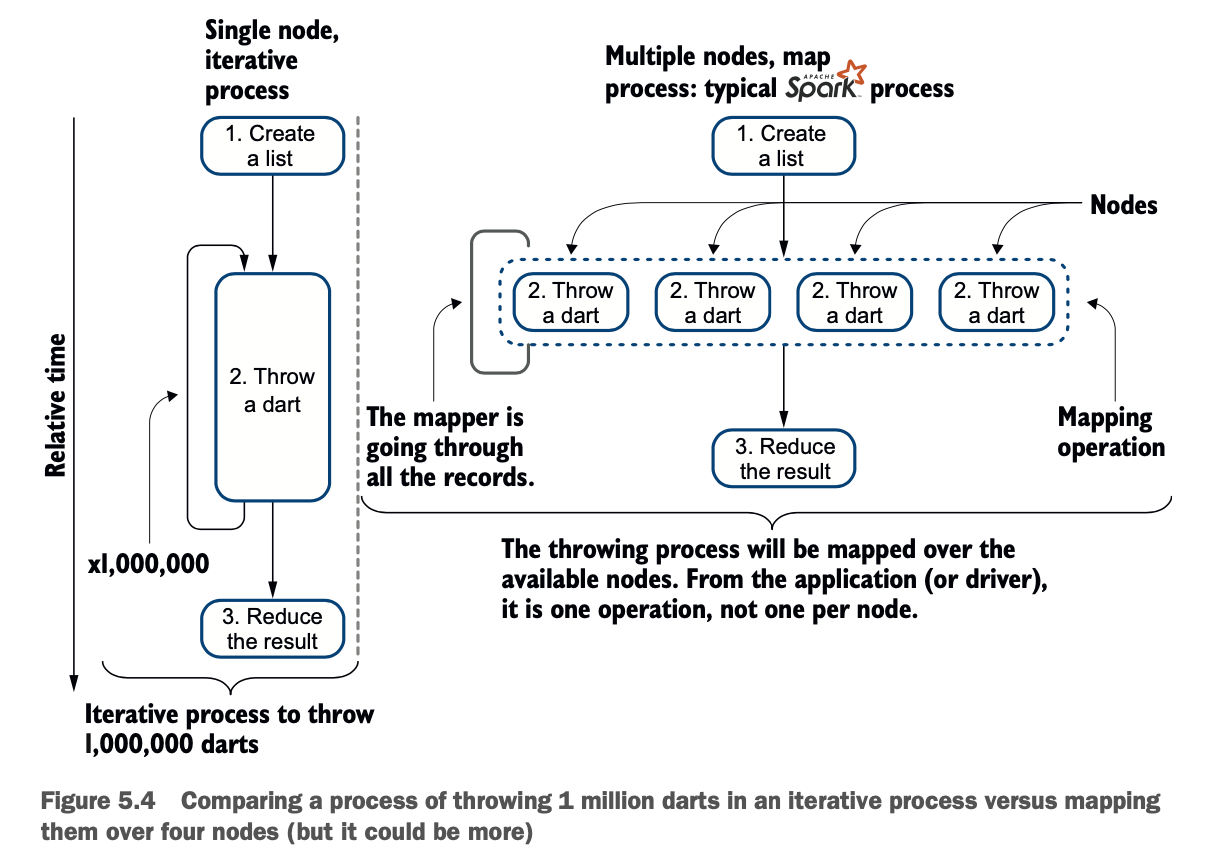
Spark将创建数据,应用转换,然后应用一个动作--这是Spark的经典操作方式。流程(如图5.3所示)如下。
打开一个Spark会话。
Spark创建一个数据集,每投一次镖就包含一行。投镖次数越多,你对π的近似值就越精确。
创建一个包含每次投掷结果的数据集。
将对圆的面积有贡献的投掷次数相加。
计算两个区域的投掷次数之比,并将其乘以4,这就是π的近似值。
在总结这个过程的同时,图5.3介绍了所使用的方法,以及涉及到哪些组件。你在第2章中了解了其中的一些组成部分。第6章还将进一步详细介绍每个组件。
 让我们看看Java代码,好吗?
让我们看看Java代码,好吗?
近似π的代码
在这一节中,你将走过这段代码,你将在本章的各种例子中使用这段代码。你将首先在本地模式下运行这段代码,然后修改这段代码以使用Java lambda函数。然后您将修改这个版本的代码以使用Java lambda函数。
Java 8引入了lambda函数,它可以不属于一个类而存在,可以作为参数传递,并按需执行。你将发现lambda函数如何帮助你(或不帮助)编写转换代码。
让我们先看看下面列表中你的应用程序的输出。

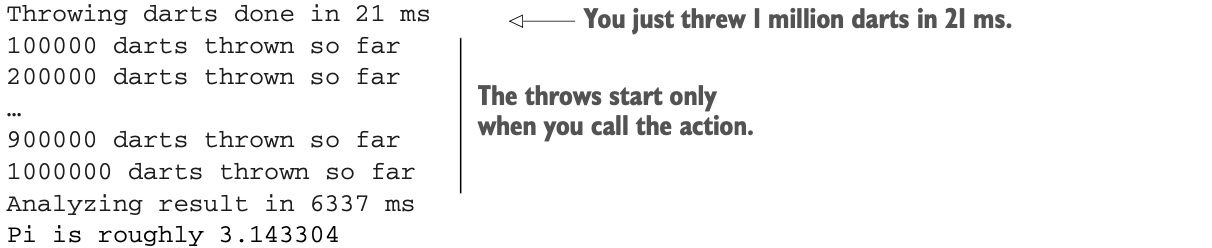 这个程序告诉你在21毫秒内投掷了100万个飞镖。然而,Spark只有在你要求它投掷飞镖时才会投掷,因为你调用了一个action来分析结果。这来自于Spark的惰性,你在第4章学到了;记住那些需要用动作来提醒的可恶的孩子们!在这个实验室中,你将会把飞镖切成小块,然后把它扔出去。
这个程序告诉你在21毫秒内投掷了100万个飞镖。然而,Spark只有在你要求它投掷飞镖时才会投掷,因为你调用了一个action来分析结果。这来自于Spark的惰性,你在第4章学到了;记住那些需要用动作来提醒的可恶的孩子们!在这个实验室中,你将会把飞镖切成小块,然后把它扔出去。
在这个实验室里,你将把处理过程分成不同的批次。我把这些切片称为,在你运行实验室之后,你可以玩玩不同位置的切片值,以更好地理解Spark如何处理这种处理方式。
LAB 实验室#100的代码在net.jgp.books.spark.ch05.lab100_pi_compute .PiComputeApp中,并在以下列表中。
 到此为止,代码是非常标准的:它使用了通常的导入的Spark类,并且正在获得一个会话。你会注意到对currentTimeMillis()的调用,以衡量时间花费在哪里。
到此为止,代码是非常标准的:它使用了通常的导入的Spark类,并且正在获得一个会话。你会注意到对currentTimeMillis()的调用,以衡量时间花费在哪里。
 在这个片段中,你从一个整数列表中创建一个数据集,并将其转换为一个数据框架。当你从一个列表中创建一个数据集时,你需要向Spark提供一个对应的数据类型--因此使用了Encoders.INT()参数。
在这个片段中,你从一个整数列表中创建一个数据集,并将其转换为一个数据框架。当你从一个列表中创建一个数据集时,你需要向Spark提供一个对应的数据类型--因此使用了Encoders.INT()参数。
这个数据框架的目的只是为了在一个叫做映射的操作中,在尽可能多的节点上调度处理。在传统的编程中,如果你想投掷100万个飞镖,你就会在一个线程中,在一个节点上使用一个循环。这不能扩展。在一个高度分布式的环境中,你把投掷飞镖的过程映射到你的节点上。图5.4比较了这些过程。
换句话说,增量DF的每一行都被传递给DartMapper的实例,这个实例在集群的所有物理节点上:
 在清单5.3中你会看到DartMapper()。
在清单5.3中你会看到DartMapper()。
减少操作带来了结果:圆圈中飞镖的数量。在类似的方式,reduce操作在你的应用程序中是透明的,只包含一行代码:
 你会在清单5.3中看到DartReducer()。
你会在清单5.3中看到DartReducer()。
我可以将应用程序的过程总结如下:
创建一个列表,它将用于映射数据。
映射数据(扔飞镖)。
计算结果。
 让我们来看看清单5.3中映射和还原操作的代码。
让我们来看看清单5.3中映射和还原操作的代码。
继续前进 你可以通过将numberOfThrows类型从int改为long来练习这个实验室。如果你使用Eclipse这样的IDE,你会直接看到它对你的代码的其余部分的影响。这个例子的另一个转折:当你调用你的master时,试着加入slices变量(或它的一部分),就像.master("local[*]")一样,看看它是如何影响性能的(当你使用更多的内核时,这将会更明显)。

 让我们分析一下使这个类工作所需的Function代码。我将去掉清单5.3中的所有业务逻辑,并带你了解这些Function代码。为了使用,映射器需要实现一个MapFunction<Row,Integer>,这意味着映射函数call()将得到一个Row并返回一个Integer。在清单5.2中,你看到调用map()函数的返回是一个Dataset<Integer>:
让我们分析一下使这个类工作所需的Function代码。我将去掉清单5.3中的所有业务逻辑,并带你了解这些Function代码。为了使用,映射器需要实现一个MapFunction<Row,Integer>,这意味着映射函数call()将得到一个Row并返回一个Integer。在清单5.2中,你看到调用map()函数的返回是一个Dataset<Integer>:
 类型(粗体)必须匹配:你使用的是整数,而整数在数据集、实现的类型和方法中都使用。
类型(粗体)必须匹配:你使用的是整数,而整数在数据集、实现的类型和方法中都使用。
当你调用reduce时,在清单5.2中,你使用了以下内容:
 这个类是这样的:
这个类是这样的:
 类型必须匹配。
类型必须匹配。
我刚刚用了MapReduce吗?
是的,你刚刚用了! 但是MapReduce到底是什么呢? MapReduce是一种在分布式环境下将工作负载分散到服务器集群上的方法。
一个MapReduce应用由映射操作和reduce方法组成,映射操作执行过滤和排序(比如将学生按名字排序到队列中,每个名字一个队列),reduce方法执行汇总操作(比如统计每个队列中的学生人数,得出名字频率)。MapReduce框架通过调集分布式服务器来协调处理,并行运行各种任务,管理系统各部分之间的所有通信和数据传输,并提供冗余和容错功能。如果你只有一台服务器,它的工作原理是一样的,因为你仍然有许多任务。
下图说明了MapReduce的原理。
最初的MapReduce理念于2004年发表在谷歌的一篇论文中。此后,它已经在各种产品中实现。最流行的实现仍然是Apache Hadoop。
在本章的例子中,MapReduce的使用很简单,因为我们执行的是简单的原子操作。在更复杂的场景中,复杂度会变成指数级的。这就是Hadoop复杂的原因之一:所有的东西都是MapReduce作业(有些工具可以掩盖复杂性)。在Apache Spark中,复杂性从一开始就被隐藏了,但如果你想的话,Spark可以让你进行低级的操作,就像你在本章所做的那样。
综上所述,Spark简化了MapReduce的处理,而且,很多时候,你甚至没有意识到自己在进行MapReduce操作。
互联网上有更多关于MapReduce的资源。YouTube有一个使用扑克牌的MapReduce的有趣解释:www.youtube.com/watch?v=bcjSe0xCHbE。(提示:如果你不想睡着的话,请把播放速度提高一倍)。
当然,你也可以查看维基百科的页面,对于介绍来说,略微太过科学(但你刚刚得到了一个,对吧?),https://en.wikipedia.org/wiki/MapReduce。
所以,看起来令人惊讶或震惊的是,Spark会做MapReduce,但不需要你做MapReduce。
本边栏中的信息改编自维基百科。
什么是Java中的lambda函数?
在上一节中,你通过使用类进行映射和还原步骤来运行π的近似。在本节中,您将(重新)发现一些关于Java中的lambda函数。在下一节(5.1.4)中,您将运行相同的应用程序,用lambda函数代替类来逼近π。如果您熟悉Java中的lambda函数,请直接跳到5.1.4节。
对软件工程师来说,编写一个类或一个lambda函数往往是一个有品味的事。重要的是,当你看到它时,你要识别它。
尽管Java目前的版本是11,但我不断地看到年轻的开发人员带着Java 7的知识进入工作岗位,而包括lambda函数在内的较新的功能仍然不受欢迎。本书的目标并不是教你Java 8,但我为一些不那么显眼(但却很好)的特性提供了一些Java提醒。
什么是JAVA LAMBDA函数?你可能熟悉Java中的lambda函数。如果您不熟悉,Java 8 引入了一种新的函数类型,它可以不属于一个类而被创建。Lambda函数可以作为参数传递,并按需执行。这是Java向函数式编程迈出的第一步。lambda函数的符号是<variable>-><function>。
在源代码库中,net.jgp.books.spark.ch05.lab900_simple_lambda.SimpleLambdaApp包含了一个使用列表的lambda函数的例子。它将对一个法语名字的列表进行两次迭代,并建立它们的组成形式,如以下:
 第一次迭代用一行代码完成,第二次迭代用几行代码完成,显示了lambda函数中的块语法。下面列举了这个过程。
第一次迭代用一行代码完成,第二次迭代用几行代码完成,显示了lambda函数中的块语法。下面列举了这个过程。
 Lambda函数可以让你写出更紧凑的代码,避免重复一些枯燥的语句;在清单5.4中你不需要循环。然而,可读性可能会受到影响。尽管如此,无论你是喜欢还是讨厌lambda函数,你都会在你将要处理的代码中看到越来越多的lambda函数,无论是在本书中还是在你的职业生活中。在下一节中,您将使用几个lambda函数重写代码来逼近π。
Lambda函数可以让你写出更紧凑的代码,避免重复一些枯燥的语句;在清单5.4中你不需要循环。然而,可读性可能会受到影响。尽管如此,无论你是喜欢还是讨厌lambda函数,你都会在你将要处理的代码中看到越来越多的lambda函数,无论是在本书中还是在你的职业生活中。在下一节中,您将使用几个lambda函数重写代码来逼近π。
用lambda函数逼近π
在前面的章节中,你看到了如何通过使用类来计算π的近似,然后你读到了lambda函数。在这一节中,你将把这两方面结合起来:通过Java lambdas用Spark逼近π,并实现一个基本的MapReduce应用。
你会发现一个替代的方法来编写清单5.2和5.3中的代码:通过用Java lambda函数替换mapper和reducer类。图5.5与图5.3类似,描述了这个过程。清单5.5对代码进行了深入研究。
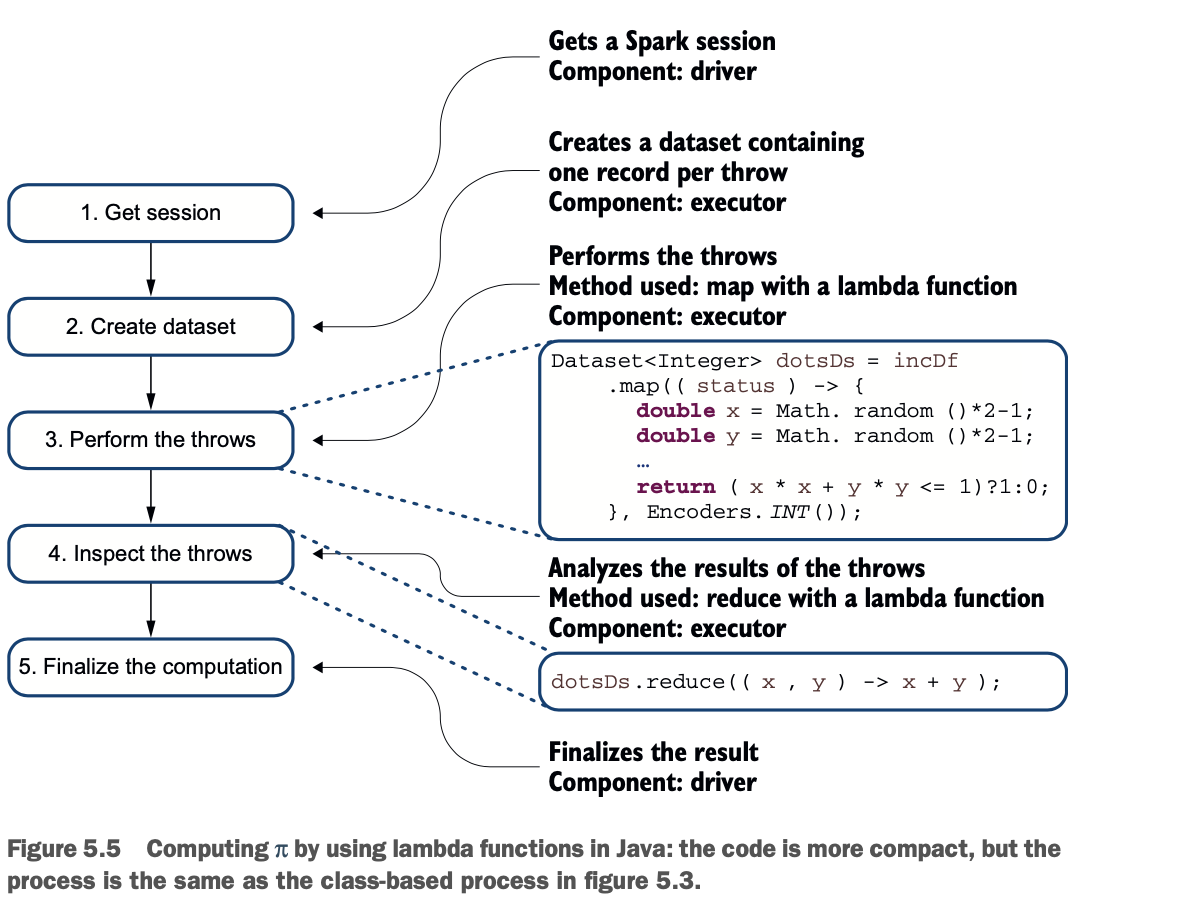

 这些lambda函数做的操作和清单5.3中的类一样。第一个lambda随机投掷飞镖,做映射操作。第二个lambda函数通过将结果相加来执行reduce操作。
这些lambda函数做的操作和清单5.3中的类一样。第一个lambda随机投掷飞镖,做映射操作。第二个lambda函数通过将结果相加来执行reduce操作。
源代码肯定更加紧凑(我也只保留了主要的差异)。然而,对于一个不熟悉lambda函数的Java软件工程师来说,这段代码可能会比较难读。
与Spark互动
在到目前为止的所有例子中,你只使用了一种方式连接到Spark:使用本地模式,其中Spark架构的每个组件都在同一台机器上无缝运行。至少有三种方式可以连接到Spark。在本节中,您将阅读各种交互方式、它们的优势以及它们的用例。了解这些信息非常重要,因为你正在部署你的应用程序的路上。
你将研究三种与Spark交互的方式。
本地模式,这当然是开发者首选的方式,因为所有的东西都运行在同一台计算机上,不需要任何配置。
集群模式,通过资源管理器,在集群中部署你的应用程序
互动模式,直接或通过基于计算机的笔记本,这可能是数据科学家和数据实验者的首选方式。
我们要带着笔记本回学校了吗?
小时候,我很喜欢暑假结束的时候,因为我会跟妈妈去买新的笔记本。由于是在法国和摩洛哥长大,我和姐姐们可以接触到这么多的笔记本:文字、绘画、科学、音乐、数学,还有图画纸,各种纸质重量的都有。科学笔记本大概是我的最爱,有交替的页面,一个正方形的页面(像图形纸一样),一个空白的页面。你可以在正方形的页面上做笔记,在空白页上画示意图、花、身体的各个部位等等。(我还可以告诉你,我对美国缺乏产品感到多么失望,但这不是真正的重点)。
计算机笔记本和我年轻时的科学笔记本一模一样:你可以在一个 "页面 "上做笔记、执行代码、显示图表等等。当然,因为它们是数字化的,你可以很容易地分享这些笔记本。有些工具还提供了协作功能。笔记本被数据科学家广泛用于实验数据,同时做笔记,在某些情况下,还可以显示图形。
笔记本可以作为软件产品使用。两个开源产品是Jupyter(http://jupyter.org/)和Apache Zeppelin(https://zeppelin.apache.org/)。也有一些托管的商业产品。IBM有Watson Studio(www.ibm.com/cloud/watson-studio),Databricks提供统一数据分析平台(https://databricks.com/product/unified-analytics-platform)。
本地模式
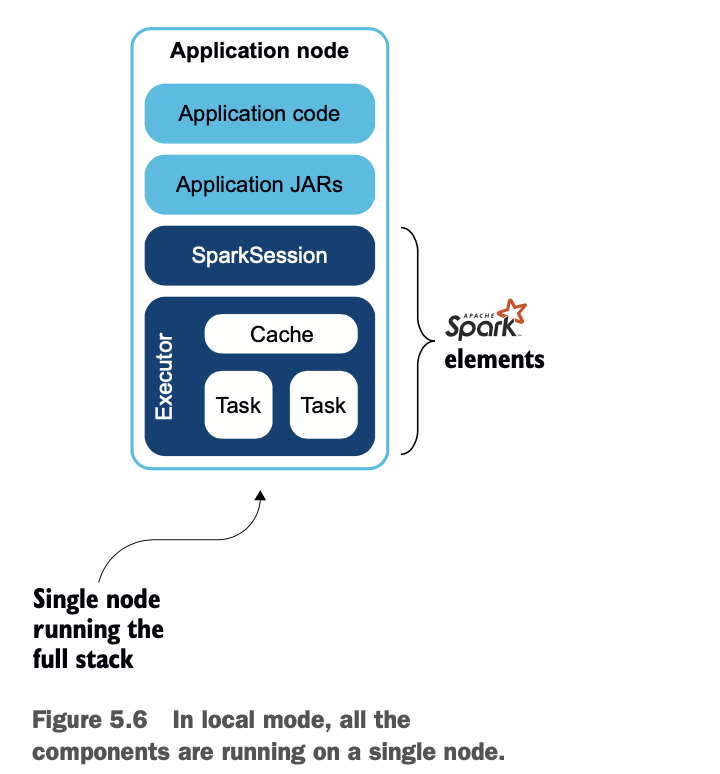
Spark的本地模式是我最喜欢Spark的一点。本地模式可以在同一台机器上实现所有的Spark组件,无论是笔记本电脑还是服务器。
你不需要安装任何软件。本地模式可以让开发团队的工程师在几分钟内上岗:下载Eclipse,克隆一个项目,你的新软件工程师就可以使用Spark和大数据了。本地模式允许您的开发人员在一台机器上进行开发和调试。
图5.6总结了堆栈。
在幕后,Spark启动了所需的机器,以建立一个主控和工人。在本地模式下,你不必提交JAR文件,Spark会设置正确的类路径,所以你甚至不必处理JAR冲突。
 要在本地模式下启动Spark,就像你在前面的例子中所做的那样,你只需通过指定主节点为本地节点来启动一个会话。
要在本地模式下启动Spark,就像你在前面的例子中所做的那样,你只需通过指定主节点为本地节点来启动一个会话。
.master("local")以下是在本地模式下获取或创建会话的完整代码:
SparkSession spark = SparkSession.builder().appName("My application") .master("local")
.getOrCreate(); 你可以通过在括号([...])之间指定线程数来申请。
SparkSession spark = SparkSession.builder() .appName("My application") .master("local[2]")
.getOrCreate(); 默认情况下,本地模式将以一个线程运行。
集群模式
在集群模式下,Spark在多节点系统中表现为有一个master和worker,正如你在第2章中看到的那样。你可能还记得,主站将工作负载分派给worker,然后由worker进行处理。集群的目标是提供更多的处理能力,因为每个节点都将其CPU、内存和存储(在需要时)带到集群中。
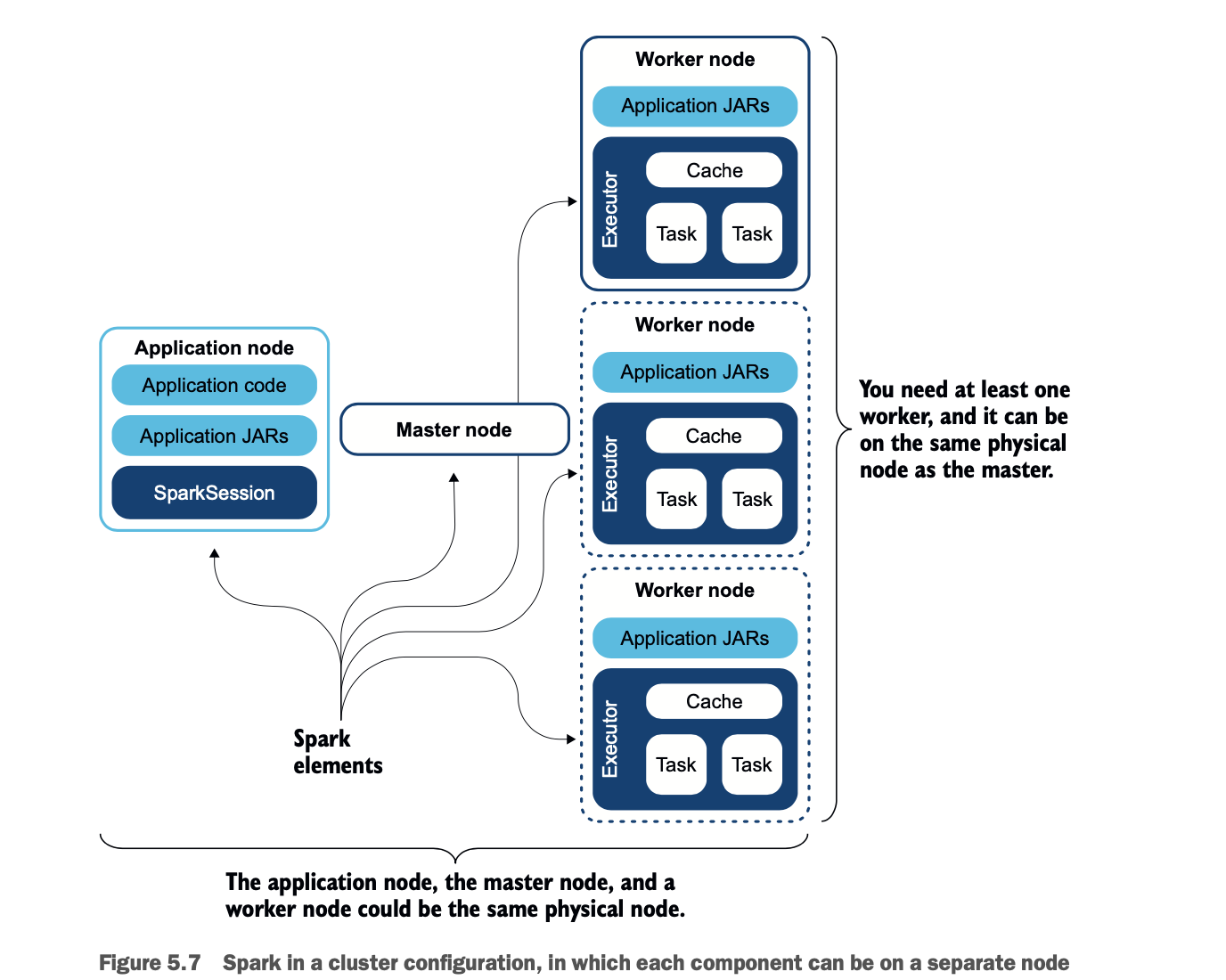
在同一个worker节点上启动几个worker也是可能的,但我没有找到一个好的用例,也没有看到好处,worker将使用配置的或可用的资源。图5.7描述了集群堆栈。
让我们来走一遍这个集群堆栈。左边是你的应用节点。它包含你的应用代码,它被称为驱动程序,因为它驱动Spark。应用节点还包含了你的应用所需的额外JAR。应用程序将通过使用Spark库在Spark上打开一个会话。
master,在图的中心,包含了Spark库,其中包括作为主节点运行的代码。
worker,在右边,有应用程序JAR和Spark库来执行代码。worker也有连接到master的二进制文件。
你正在学习所有这些概念,因为你正在部署你的工作的路上,而部署会对你的构建策略产生影响。
在某些情况下,为了方便部署,你会希望创建一个uber JAR,其中包含你的应用程序和它的依赖关系。在这种情况下,你的 uber JAR 不应该包含 Hadoop 或 Spark 库;这些库已经被部署了,因为它们被包含在 Spark 发行版中。构建uber JAR可以通过Maven自动完成。
Hadoop是什么?
Hadoop是一头大象。Hadoop也是MapReduce的流行实现。和Spark一样,它也是开源的,由Apache基金会管理。与Spark不同的是,它是一个复杂的生态系统,要进入这个系统,对算法的类型(主要是MapReduce)和存储(主要是磁盘)都有限制。Hadoop世界的一切都在慢慢改变,让它变得更容易,但Spark已经来了。
Spark使用一些Hadoop库,这些库包含在你部署在每个节点上的Spark运行时中。
是的,Hadoop是一头大象的名字。Hadoop创造者Doug Cutting的儿子给一只黄色的大象毛绒玩具取名为Hadoop--因此Hadoop的标志是一只黄色的大象。
什么是uber JAR?
JAR是一个Java档案文件。当你把所有的.java文件编译成.class时,你会把它们全部合并到一个JAR文件中。你可能已经知道了。
uber JAR(也被称为超级JAR或胖JAR)是一个高于(字面意思是德语翻译为über)其他JAR的JAR。uber JAR包含了你的应用程序的大部分(如果不是全部)依赖关系。这样一来,后勤工作就变得非常简单,因为你只需要一个JAR。
JAR系统有时在Java开发者中被称为JAR地狱,因为当你结合越来越多的库和不同的依赖关系时,JAR的多个版本会变得非常混乱。例如,Elasticsearch客户端库v6.2.4使用了Jackson core v2.8.6(通用解析器)。Spark v2.3.1使用相同的库,但在v2.9.6.包管理器,如Maven,试图管理这些依赖关系,但有时一个库的后期版本与旧版本不兼容。这些版本差异会把你带入JAR地狱。而有时要想出来是很困难的。
如你所知,JAR是一个Java存档。Java有一个叫做jar的工具,它的工作原理就像UNIX的tar命令。你可以把你的类放到JAR中,或者说存档。你可以解压或取消JAR文件,当然,你也可以重建你的存档,或重新JAR。我希望我在这里没有太过刺耳......
让我们回到构建uber JAR的问题上。每次部署时,uber JAR都会被重建。构建uber JAR的过程包括取消JAR化同一目录下所有项目的JAR,然后Maven会重新JAR化所有的JAR。然后Maven会把所有的类重新JAR到一个更大的uber JAR中。
这就会产生很多问题。以下是两个最常见的问题。
有些JAR是有签名的 解除JAR后再重新JAR,作为不同存档的一部分,会破坏签名。类似的问题也会发生在清单文件上,它们会被覆盖。
大小写敏感度可能是个问题。如你所知,MyClass和Myclass是不同的。但是当你在一个不区分大小写的文件系统上解开JAR时(例如,Windows),一个会覆盖另一个,一个之后将无法使用,在你的代码中产生随机的ClassNotFoundException异常。当开发人员使用Windows进行构建,然后从他们的工作站进行部署时,这种情况就会发生--虽然很疯狂,但这是事实。这也是使用(Linux)构建服务器进行持续集成和持续交付(CICD)过程的另一个原因。
Uber JARs是部署工作的强大工具,但要确保你的构建操作是在大小写敏感的文件系统上进行的,不要打包Spark库,并且要非常小心我刚才描述的问题。
第6章将引导你完成部署应用程序的各个步骤;在这个阶段,你还在发现部署应用程序的关键概念。细节会有的。
有两种方法可以在集群上运行应用程序。
你通过使用spark-submit shell和你的应用程序的JAR提交一个作业。
你在应用程序中指定主程序,然后运行你的代码。
向spark提交作业 在集群上执行应用程序的一种方法是提交一个作业,作为一个打包的JAR,提交给Spark。这类似于在大型机上提交作业。要做到这一点,请确保以下几点。
你用你的应用程序建立一个JAR。
你的应用程序所依赖的所有JAR都在每个节点上或uber JAR中。
在你的应用程序中设置集群Master
在集群上运行应用程序的另一种方式是简单地在应用程序中指定主控的Spark URL。你的要求和提交作业时一样。
你用你的应用程序构建一个JAR。
你的应用程序所依赖的所有JAR都在每个节点上或在uber JAR中(假设你提交的是uber JAR)。
Scala和Python的交互模式
在前面的小节中,你看到了如何以编程方式或通过提交作业与Spark进行交互。还有第三种方式可以与Spark进行交互。你也可以在完全交互模式下运行Spark,这允许你在shell中操作大数据。
除了shell之外,你还可以使用Jupyter和Zeppelin等笔记本。不过,这些工具更多是针对数据科学家的。
Spark提供了两个shell,它们接受Scala、Python和R,在本节中,你将看到如何运行Scala和Python shell。(教授这些语言超出了本书的范围)。
图5.8说明了在交互模式下使用Spark时的架构。它与集群模式和图5.7类似。唯一的区别在于你开始工作会话的方式。
 SCALA SHELL
SCALA SHELL
Spark提供了一个交互式的Scala shell。与任何shell一样,你可以输入命令。让我们看看如何运行它,检查Spark的版本,并在Scala中运行π应用程序的近似值。
要在本地模式下运行交互式模式,去你的Spark的bin目录下运行这个。
$ ./spark-shell如果你有一个集群,你可以在命令行中使用--master <Master's URL>来指定你的集群的主URL。你可以通过在命令行中使用--help参数来查看帮助。
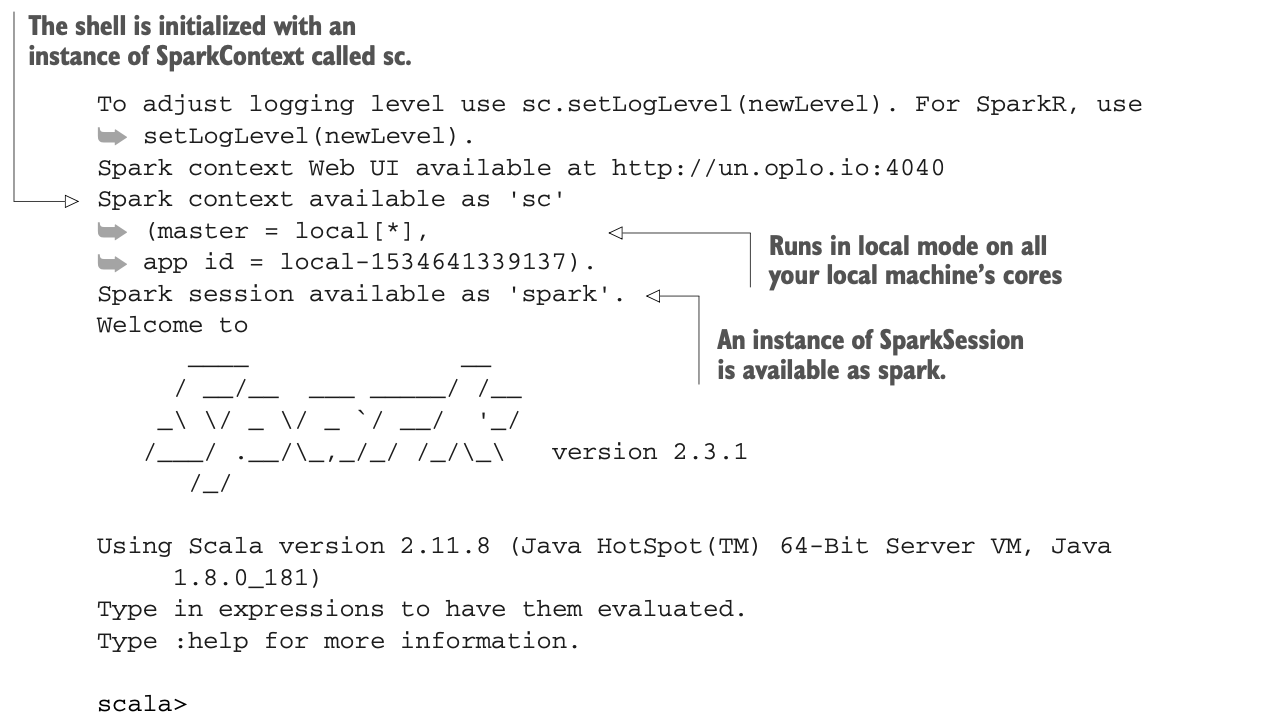 当然,要想进一步使用shell,你需要了解Scala,这在本书的上下文中完全不是必需的(参考附录J来了解更多)。本小节的其余部分将向你展示Scala中的基本操作,你将看到与Java的相似之处。如果你现在想离开(我可以理解),你可以按Ctrl-C键退出shell。
当然,要想进一步使用shell,你需要了解Scala,这在本书的上下文中完全不是必需的(参考附录J来了解更多)。本小节的其余部分将向你展示Scala中的基本操作,你将看到与Java的相似之处。如果你现在想离开(我可以理解),你可以按Ctrl-C键退出shell。
你可以尝试一些事情,比如显示Spark的版本。
scala> sc.version
res0: String = 2.3.1或者:
scala> spark.sparkContext.version
res1: String = 2.3.1因为计算π的近似值是本章的主题,下面是如何在交互式shell中进行计算。这是你可以在解释器中输入的Scala代码段。

 当你在shell中运行这段代码时,你会得到这样的输出:
当你在shell中运行这段代码时,你会得到这样的输出:
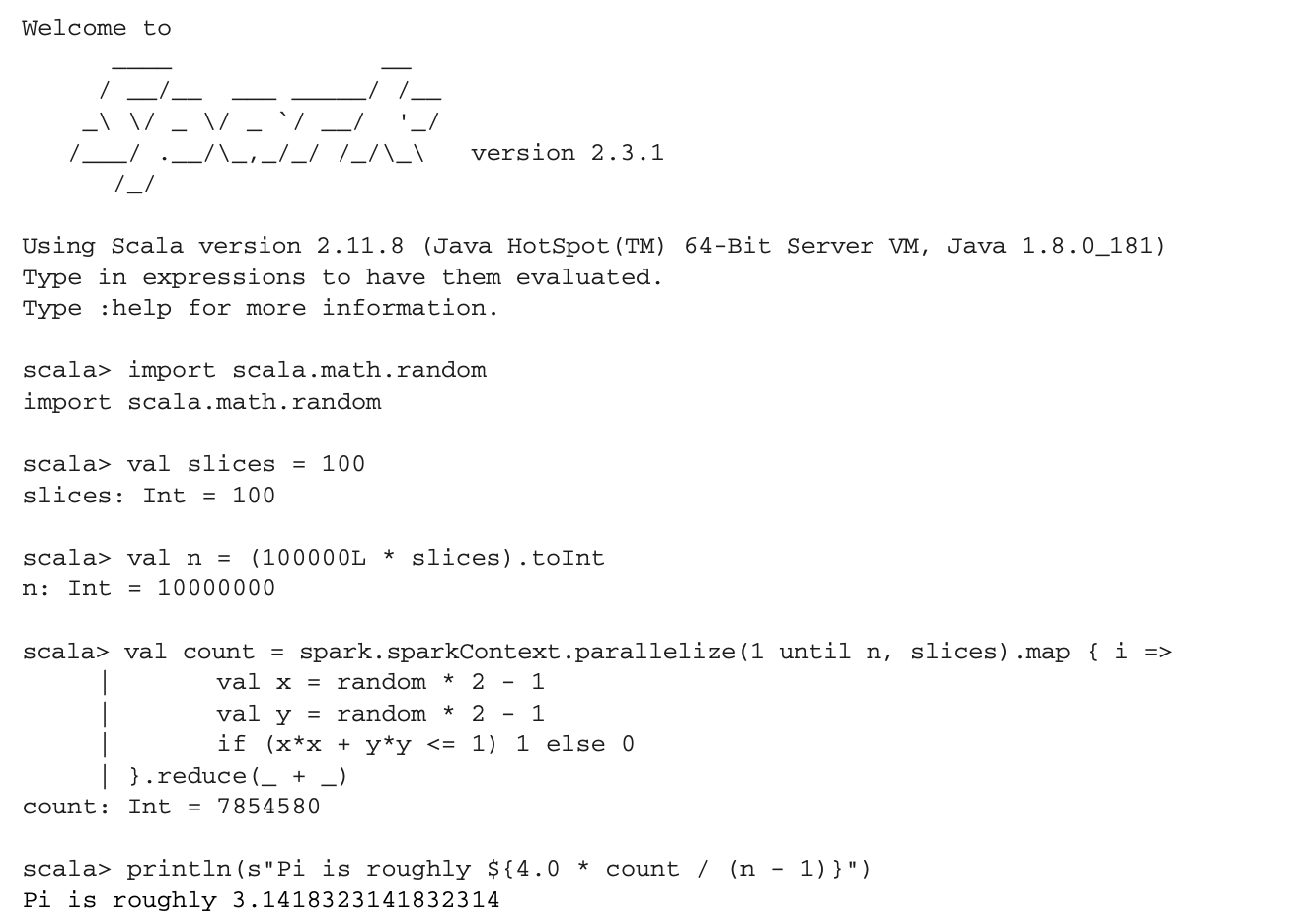 如你所见,你在Scala中运行的代码与在Java中运行的代码类似。而且不用深究语法,你肯定能认出上一节中你的Java应用的一些元素。你也可以看到MapReduce操作。
如你所见,你在Scala中运行的代码与在Java中运行的代码类似。而且不用深究语法,你肯定能认出上一节中你的Java应用的一些元素。你也可以看到MapReduce操作。
如果你想了解更多关于Scala的知识,可以看看Daniela Sfregola的《Get Programming with Scala》(Manning,2017,www.manning.com/books/get-programming-with-scala)。
我们来看看Python shell。
PYTHON SHELL
Spark还提供了一个交互式的Python shell。与任何shell一样,你可以输入命令。让我们看看如何运行它,检查Spark的版本,并运行用于近似π的Python应用程序。
要在本地模式下运行交互式模式,去你的Spark的bin目录下运行这个。
$ ./pyspark如果你有一个集群,你可以在命令行中使用--master <Master's URL>来指定集群的主URL。你可以通过在命令行使用--help参数来查看帮助。然后你应该得到以下信息:
 要退出 shell,可以使用 Ctrl-D 或调用 quit() 。如果你喜欢PySpark v3,在启动PySpark shell之前,将PYSPARK_PYTHON环境变量设置为python3:
要退出 shell,可以使用 Ctrl-D 或调用 quit() 。如果你喜欢PySpark v3,在启动PySpark shell之前,将PYSPARK_PYTHON环境变量设置为python3:
$ export PYSPARK_PYTHON=python3
$ ./pyspark而你应该得到这个:
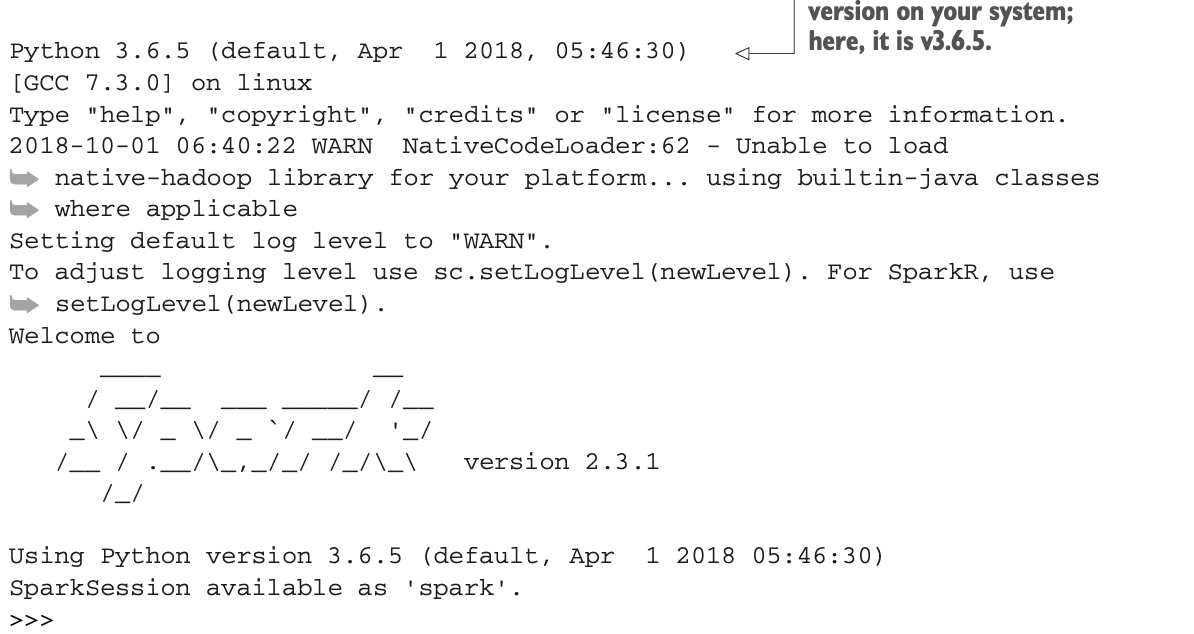 本章剩下的部分假设您正在运行 Python v3。 从这一点来看,您需要用到
本章剩下的部分假设您正在运行 Python v3。 从这一点来看,您需要用到
来了解一下Python。你可以显示Spark的版本。
>>> spark.version
'2.3.1' 在Python中π的近似可以这样做:
 小程序将首先抛出所有的飞镖。当你在shell中键入你的代码时,shell就是这样表现的:
小程序将首先抛出所有的飞镖。当你在shell中键入你的代码时,shell就是这样表现的:
 如果你想了解更多关于Python的知识,可以看看Naomi Ceder写的《快速Python书》(Manning,2018年),现在是第三版(www.manning.com/books/the-quick-python-book-third-edition)。
如果你想了解更多关于Python的知识,可以看看Naomi Ceder写的《快速Python书》(Manning,2018年),现在是第三版(www.manning.com/books/the-quick-python-book-third-edition)。
概要
Spark可以在不摄取数据的情况下工作,它可以生成自己的数据。
Spark支持三种执行模式:本地模式、集群模式和交互模式。
本地模式允许开发人员在几分钟内开始Spark开发。
集群模式用于生产。
你可以向Spark提交一个作业或连接到Master。
驱动程序应用程序是你的main()方法所在的地方。
Master节点知道所有的Worker节点。
执行发生在Worker上。
Sparks在集群模式下处理将你的应用JAR分发到每个worker节点。
MapReduce 是在分布式系统中处理大数据的常用方法。 Hadoop是其最流行的实现。Spark掩盖了它的复杂性。
持续集成和持续交付(CICD)是一种敏捷方法论,鼓励频繁的集成和交付。
在Java 8中引入的Lambda函数,允许你在类的范围之外拥有函数。
uber JAR在一个文件中包含了一个应用程序的所有类(包括依赖项)。
Maven可以自动构建uber JAR。
Maven可以在部署JAR文件的同时部署你的源代码。
Spark的map和reduce操作可以使用类或lambda函数。
Spark提供了一个Web界面来分析作业和应用程序的执行情况。
交互模式允许你直接在shell中键入Scala、Python或R命令。也可以借助Jupyter或Zeppelin等笔记本实现交互。
π(pi)可以通过向镖靶投掷飞镖并测量其比例来估算。圈内和圈外的飞镖。